
The flickering neon sign outside cast long shadows across the dusty server room. In this concrete jungle, data whispers secrets, and vulnerabilities are the forgotten alleyways where fortunes are made or lives are ruined. We're not here to crack systems today; we're here to dissect them, to understand the whispers before they become screams. Today, we're diving into the dark art of Format String vulnerabilities, specifically within the venerable `printf` family of functions. Forget the flashy exploits for a moment. True mastery lies in understanding the enemy's tools—and then building impenetrable fortresses. This isn't about breaking in; it's about locking down the doors so tight that even ghosts can't get through.
Format string vulnerabilities are a classic. They’re the kind of bugs that have been around since C was king, yet they still pop up, often in unexpected places. We're going to peel back the layers of a typical `printf` exploit, not to show you how to execute one, but to arm you with the knowledge to detect, prevent, and remediate them. Think of this as a blue team's guide to the ghost in the machine.
Understanding the `printf` Family and How It Can Be Abused
The `printf` function and its relatives (`sprintf`, `fprintf`, `vprintf`, etc.) are workhorses in C programming for formatted output. They take a format string and a variable number of arguments, substituting placeholders in the format string with the string representation of the arguments. For instance, `printf("Hello, %s!\n", username);` substitutes `%s` with the value of the `username` variable.
The vulnerability arises when a format string is controlled, directly or indirectly, by user input. When `printf` encounters format specifiers like `%x`, `%s`, `%n`, or `%p` in a string that it wasn't designed to process, it can lead to serious security issues. The most dangerous of these is `%n`.
"The `printf` function is a gateway. If you don't control what goes through it, you're inviting chaos." - cha0smagick
The Menace of `%n`
Unlike other format specifiers that *read* from the argument list and *print* data, the `%n` specifier is unique: it *writes* the number of bytes successfully written so far by `printf` to the memory address pointed to by the corresponding argument. If an attacker can control both the format string and the arguments passed to `printf`, they can craft a string that directs `printf` to write arbitrary data to arbitrary memory locations.
This can lead to:
- Memory Disclosure: Using specifiers like `%x`, `%p`, and `%s` can leak memory addresses, stack contents, and heap information, aiding in further exploitation.
- Arbitrary Memory Writes: Crucially, `%n` allows attackers to overwrite critical data structures, function pointers, return addresses on the stack, or even arbitrary memory locations. This is the gateway to code execution.
- Denial of Service: Malformed format strings can crash applications, leading to a denial of service.
Anatomy of a Format String Exploit (Defensive Perspective)
Let's break down how an attacker might exploit a hypothetical vulnerable function. Imagine a simple C program designed to print user-provided messages:
#include <stdio.h>
void vulnerable_function(char *user_input) {
printf(user_input); // Vulnerable line!
}
int main(int argc, char **argv) {
if (argc != 2) {
printf("Usage: %s <message>\n", argv[0]);
return 1;
}
vulnerable_function(argv[1]);
return 0;
}
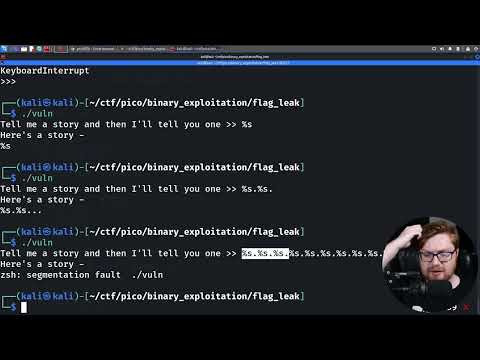
If an attacker provides the input `"%x %x %x %x %x %x %x %x"`, the program will print several hexadecimal values from the stack. This is useful for information gathering. They might see return addresses, saved base pointers, and other sensitive data.
Leveraging `%n` for Control
The real power comes with `%n`. An attacker can use techniques like:
- Writing specific values: By carefully crafting strings with `%n` specifiers and padding, an attacker can write specific byte sequences to memory. They might use specifiers like `%1234x` to control padding or `%1234$n` to specify which argument to write to.
- Overwriting Return Addresses: The ultimate goal is often to overwrite the return address on the stack with the address of shellcode or a useful gadget (like ROP gadgets).
For instance, a string like `AAAA%n` would write the value `4` (the number of 'A's printed) to the memory location pointed to by the first argument passed to `printf`. If the attacker controls that first argument and it points to a location they want to overwrite, they've achieved a write.
Consider a scenario where the attacker wants to overwrite a specific memory address `0xdeadbeef` with the value `0x41414141` (which is 'AAAA' in ASCII). They might craft an input that includes:
- The target address `0xdeadbeef`
- Padding to reach that address
- Format specifiers to write the desired value.
The specific bytes to be written need to be injected into the format string itself, or passed as arguments, and then the `%n` specifier is used to write the count of characters printed *up to that point* into the memory location specified by the corresponding argument pointer. This requires precise calculation of offsets and values.
Defensive Strategies: Building the Fortress
The best defense against format string vulnerabilities is not to use user-controlled input directly as a format string. Ever. Unless absolutely necessary and with extreme caution.
1. Explicitly Provide the Format String
The golden rule: Always provide a format string literal. Instead of:
printf(user_input); // BAD!
Use:
printf("%s", user_input); // GOOD!
This tells `printf` to treat `user_input` as data to be printed, not as a format string itself. Any special characters within `user_input` will be printed literally, preventing the interpretation of `%n` or other format specifiers.
2. Input Validation and Sanitization
If you absolutely *must* process user input that might contain format specifiers (a rare and risky scenario), rigorous validation is key. Strip out or escape all `%` characters. However, this is often a losing battle, as attackers are creative and can find ways around simple filtering. It's far safer to avoid this scenario entirely.
3. Compiler Security Features
Modern compilers offer protections:
- Stack Canaries: These random values are placed on the stack before return addresses. If an overflow occurs and overwrites the return address, the canary value will change, and the program will detect the corruption before returning, preventing the exploit.
- Address Space Layout Randomization (ASLR): ASLR randomizes memory locations of key program areas (stack, heap, libraries), making it harder for attackers to predict target addresses for memory writes.
- Data Execution Prevention (DEP) / No-Execute (NX) bit: Prevents attackers from executing code injected into data segments of memory.
While these are invaluable, they don't always stop precise memory writes via `%n`. They are layers of defense, not a single silver bullet.
4. Static and Dynamic Analysis Tools
Use static analysis tools (like Coverity, SonarQube) to scan your codebase for potential format string vulnerabilities. Dynamic analysis (fuzzing) can also uncover these bugs by feeding malformed inputs to your application.
Taller Defensivo: Detección de `printf` Vulnerabilidades con Herramientas
As an operator, your job is to find these needles in the haystack before attackers do. This involves code review and the intelligent use of scanning tools.
-
Code Review for Direct `printf` Calls:
When reviewing C/C++ code, look for any direct calls to `printf`, `sprintf`, `fprintf`, etc., where the first argument is a variable that originates from external input (e.g., user input, network packets, file contents). These are red flags.
grep -r "printf(" your_source_code/ | grep -v 'printf(".*"'This basic grep command can help identify potential candidates, but it will have false positives. Manual verification is crucial.
-
Using a SAST Tool (e.g., Flawfinder):
Tools like `flawfinder` are designed to scan C/C++ source code for security flaws, including format string bugs.
flawfinder --output all --mfl 1 your_source_code/The output will categorize potential vulnerabilities by risk level. Pay close attention to 'MEDIUM' and 'HIGH' risk findings related to format strings.
-
Dynamic Analysis (Fuzzing):
For applications that accept string inputs, fuzzing is essential. Tools like AFL (American Fuzzy Lop) or libFuzzer can generate a vast number of malformed inputs, including strings with many `%` characters, to try and trigger crashes or unexpected behavior from `printf`.
A simple fuzzing setup might involve piping generated strings into your vulnerable program.
# Example with a compiled C program 'vuln_app' afl-fuzz -i input_dir -o output_dir ./vuln_app @@Monitor the output directory for crashes. Analyze any crashes using a debugger to determine if they are due to format string exploitation.
-
Runtime Monitoring for Suspicious Behavior:
In a production environment, robust logging and monitoring can help detect exploitation attempts. Look for:
- Abnormal error rates or application crashes.
- Unusual patterns in log messages that might indicate data leakage or unexpected behavior.
- System calls that deviate from normal operation.
While these are reactive measures, they are critical in an incident response scenario.
Veredicto del Ingeniero: ¿Cuándo es Aceptable Usar Input como Format String?
La respuesta corta es: **casi nunca**. La tentación existe en escenarios de debugging muy específicos o en prototipos rápidos donde la seguridad no es una preocupación inmediata. Sin embargo, la historia de la ciberseguridad está repleta de ejemplos de código "seguro para depuración" que terminó en producción y se convirtió en una puerta trasera para atacantes. Si te encuentras pensando "esto es solo para desarrollo", detente y considera el riesgo. Los principios de seguridad como las defensas en profundidad deben aplicarse desde la primera línea de código. El uso de `printf(user_input)` es un atajo que casi siempre te llevará a un camino peligroso. Adopta `printf("%s", user_input)` como tu mantra de defensa contra este tipo de ataque. Es una pequeña modificación con enormes implicaciones de seguridad.
Arsenal del Operador/Analista
- Herramientas de Análisis Estático: Flawfinder, Cppcheck, Klocwork, Coverity, SonarQube.
- Herramientas de Análisis Dinámico: AFL (American Fuzzy Lop), libFuzzer, Valgrind (para detección de memoria).
- Debuggers: GDB, WinDbg.
- Disassemblers/Decompilers: IDA Pro, Ghidra, Radare2.
- Libros Clave: "The Shellcoder's Handbook", "Practical Binary Analysis", "Hacking: The Art of Exploitation".
- Certificaciones Relevantes: Offensive Security Certified Professional (OSCP), Certified Exploit Developer (SED) de Zero-Point Security, GIAC Certified Incident Handler (GCIH).
Preguntas Frecuentes
Q1: ¿Son las vulnerabilidades de formato de cadena específicas de C?
A1: Principalmente sí, ya que `printf` y su familia son funciones del lenguaje C. Sin embargo, lenguajes que interactúan con código C subyacente o que implementan funciones de formato similares (aunque menos comunes) podrían ser susceptibles.
Q2: ¿Cómo puedo configurar un entorno seguro para probar exploits de formato de cadena?
A2: Utiliza máquinas virtuales aisladas (VirtualBox, VMware) con sistemas operativos "CTF-ready" o versiones antiguas de Linux. Asegúrate de que la red esté configurada como "Host-Only" o "Internal Network" para evitar la exposición a tu red principal. Desactiva ASLR temporalmente en el entorno de prueba si es necesario para fines de aprendizaje, pero ten en cuenta que en sistemas reales ASLR estará activo.
Q3: ¿Qué es el "offset" en el contexto de un exploit de formato de cadena?
A3: El offset se refiere a la distancia en bytes entre el inicio de la cadena de formato y el punto donde se encuentra el argumento o la dirección de memoria que se desea escribir o leer. Calcular el offset correcto es crucial para apuntar con precisión a la ubicación deseada en la memoria.
El Contrato: Fortaleciendo tu Código Contra Ataques de Formato de Cadena
Ahora que has desmantelado la amenaza, es hora de construir.
Tu desafío: Toma una función simple en C que imprima una cadena proporcionada por el usuario utilizando `printf`. Tu misión es:
- Identificar la vulnerabilidad obvia.
- Modificar la función para que sea segura, aplicando el principio de "proporcionar explícitamente la cadena de formato".
- Si puedes, crea un pequeño script de prueba en Python que intente explotar la versión vulnerable (solo para fines educativos y de demostración en un entorno controlado) y luego demuestra que tu versión modificada es resistente al mismo intento de exploit.
Publica tu código y tus hallazgos en los comentarios. Demuestra que entiendes la diferencia entre un atacante y un defensor.




